Simple Bayesian Update - Three Methods
Solving a simply binomial update problem using a grid method, MCMC, and a conjugate prior
- : Changing image and file paths
- : Changing picture and file paths
Introduction
For a given problem in Bayesian statistics, there can often be more than one way to solve it. In this article, we’ll take a very simple problem from Statistical Rethinking by Richard McElreath and solve it in three different ways.
Problem
(Adapted from Statistical Rethinking)
Imagine that you are attempting to find out what proportion of the surface of the Earth is covered in water. Rather than, say, simply look this up, you decide to do an experiment. You have a globe nearby, and so you decide to throw the globe in the air, catch it, and record whether or not you index finger was covering land or water. You try this 10 times, and hit water 7 of them. What do you believe about the proportion of the Earth’s surface which is covered in water?
First, let’s say that the true proportion of water on the surface of the Earth is , and for our purposes let’s also say that that is the probability with which a given toss will end up with your finger over water. I vaguely remember that the propertion of the Earth’s surface which is water is about 2/3, which we will represent using a prior which is distributed as . Why did we choose this prior? For a few reasons. The beta and binomial distributions are tightly linked, and in particularly the Beta is the conjugate prior of the binomial distribution, which we will use later to calculate a posterior distribution. We can think of the parameters and as being somehow related to the number of successes and failures, respectively, of a binomial. To be slightly more accurate, we can think of , , and the maximum likelihood value for the Beta pdf will occur at . A slightly non-rigorous proof is as follows:
(I feel OK about presenting this abbreviated proof because a visual examination of the Beta pdf shows just a single critical point at a maximum, so taking the final step of actually proving that the point which we found is a maximum seems superfluous, at least for our purposes).
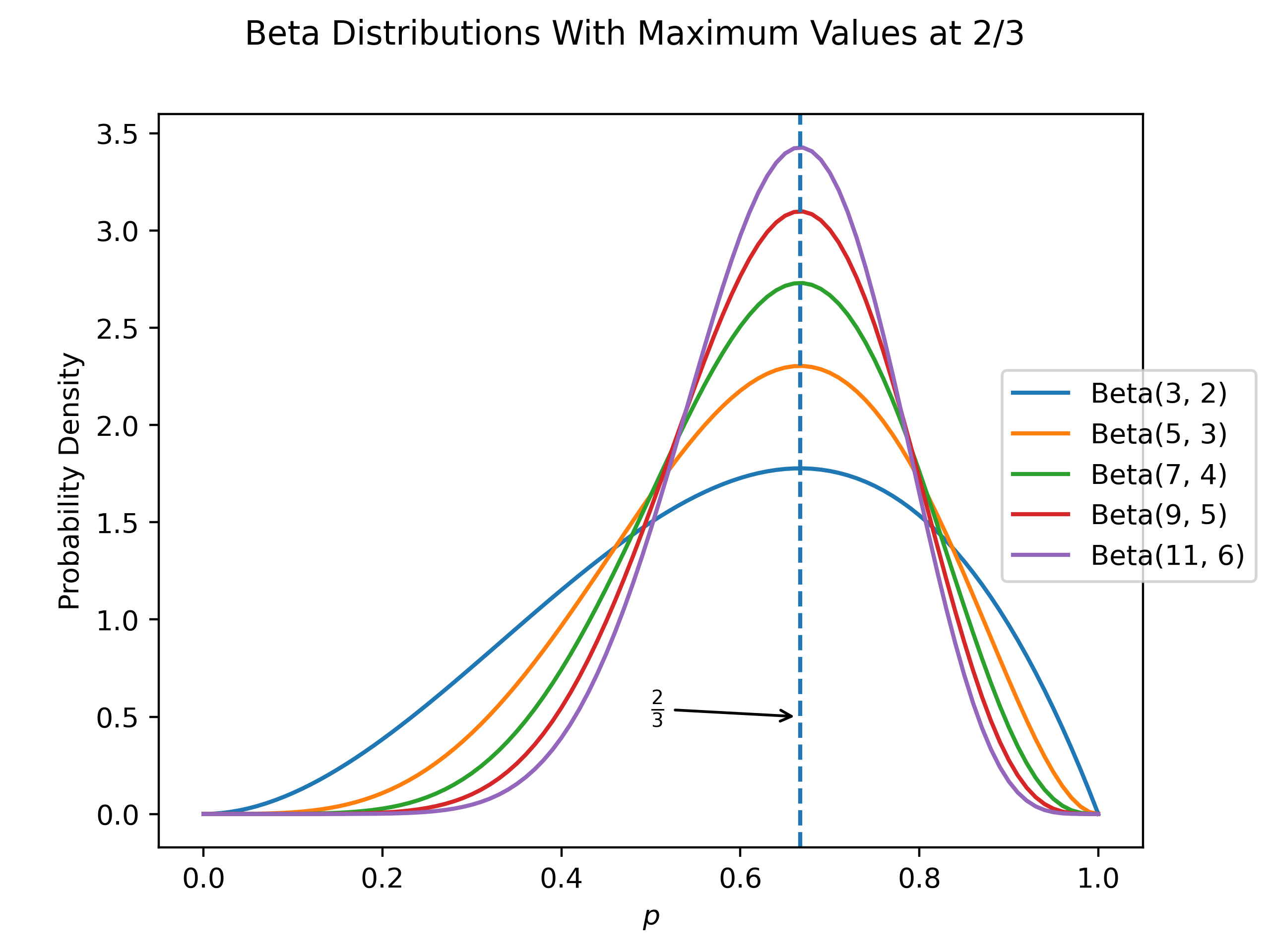
The actual numbers we choose somehow reflect our level of conviction. Visually, we can see this if we plot various beta distributions where the ratio of successes / trials is the same but the actual values are different:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.stats import beta
ps = np.linspace(0, 1, 101)
fig, ax = plt.subplots()
ax.set_xlabel("$p$")
ax.set_ylabel("Probability Density")
for alpha_param, beta_param in [(num_successes + 1, num_failures + 1) for num_successes, num_failures in [(2 * k, 1 * k) for k in range(1, 6)]]:
ax.plot(ps, beta(alpha_param, beta_param).pdf(ps), label=f"Beta({alpha_param}, {beta_param})")
ax.axvline(x=2/3, linestyle="--")
ax.annotate(r"$\frac{2}{3}$", xy=(2/3, 0.5), xytext=(0.5, 0.5), arrowprops=dict(arrowstyle="->"))
fig.legend(loc="center right")
fig.suptitle(f"Beta Distributions With Maximum Values at 2/3")
fig.savefig("differentBetas.png", dpi=400)Thus, our choice of indicates that I think that the value of is about 2/3, but I am not very confident. If I wanted I could actually use non-integer values to indicate even more uncertainty, but this should be enough for now.
Grid Method
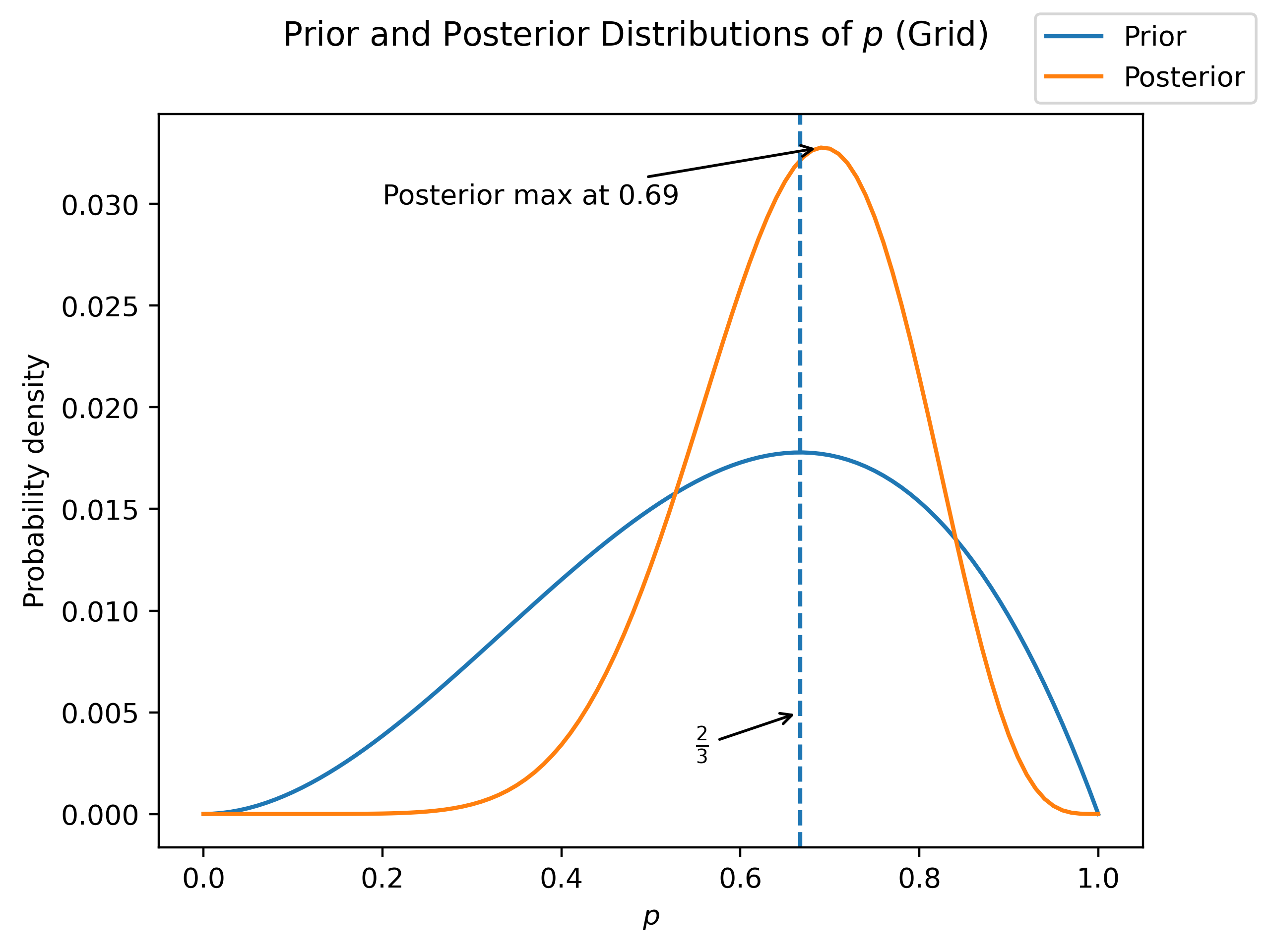
So now we can use our first method to approximate our final distribution of the propportion of water on the Earth’s surface - a grid approximation. For this, we will evaluate our prior and likelihood at a number of potential values for , and then multiply them together. If we choose a sufficiently large number of points, our approximation should be a good one!
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import binom, beta
ps = np.linspace(0, 1, 101)
alpha_param = 3
beta_param = 2
prior = beta(alpha_param, beta_param).pdf(ps)
likelihood = binom(n=10, p=ps).pmf(7)
posterior = prior * likelihood # unnormalized
posterior = posterior / np.sum(posterior) # normalized
max_posterior = np.max(posterior) # probability mass
max_posterior_index = np.argmax(posterior)
fig, ax = plt.subplots()
ax.set_xlabel("$p$")
ax.set_ylabel("Probability density")
ax.plot(ps, prior / np.sum(prior), label="Prior")
ax.plot(ps, posterior, label="Posterior")
ax.axvline(x=2/3, linestyle="--")
ax.annotate(r"$\frac{2}{3}$", xy=(2/3, 0.005), xytext=(0.55, 0.003), arrowprops=dict(arrowstyle='->'))
ax.annotate(f"Posterior max at {ps[max_posterior_index]:.2f}", xytext=(0.2, 0.03), xy=(ps[max_posterior_index], max_posterior), arrowprops=dict(arrowstyle="->"))
fig.legend()
fig.suptitle("Prior and Posterior Distributions of $p$ (Grid)")
fig.savefig("grid.png", dpi=400)So we can see that with the addition of our data, we have shifted the maximum slightly and increased our confidence (decreased the spread / variance) quite a bit!
Markov Chain Monte Carlo (MCMC)
Another method that we can use to estimate the distribution of the parameter is to use Markov Chain Monte Carlo. This method is probably one of my favourites, from a purely aesthetic perspective. MCMC allows us to construct samples from a posterior distribution, without ever calculating that distribution! Instead, it constructs a Markov Chain which converges to the posterior. When I first learnt about it, it seemed like magic, and it still seems that way to me.
To begin with, let’s be a little more formal about our model. In fact, we can write down how we believe our system works:
Where is the observed number of “water” hits (7), and is the true proportion of the Earth’s surface which is covered in water.
In order to construct our estimate, we will use PyMC. We will write down our model almost exactly the way it appears above, run it, and sample from the results.
import numpy as np
import matplotlib.pyplot as plt
import pymc as pm
from scipy.stats import gaussian_kde, beta
ps = np.linspace(0, 1, 101)
prior = beta(3, 2).pdf(ps)
n = 10
observed_k = 7
with pm.Model() as model:
p = pm.Beta("p", alpha=3, beta=2)
k = pm.Binomial("k", p=p, n=n, observed=observed_k)
samples = pm.sample(tune=2000)
combined_samples = []
for samples_chain in samples.posterior['p']:
combined_samples.extend(samples_chain)
sample_distribution = gaussian_kde(combined_samples)
posterior = sample_distribution.pdf(ps) #unnormalized
posterior = posterior / np.sum(posterior) #normalized
max_posterior_index = np.argmax(posterior)
max_posterior = np.max(posterior)
fig, ax = plt.subplots()
ax.set_xlabel("$p$")
ax.set_ylabel("Probability density")
ax.plot(ps, prior / np.sum(prior), label="Prior")
ax.plot(ps, posterior, label="Posterior")
ax.axvline(x=2/3, linestyle="--")
ax.annotate(r"$\frac{2}{3}$", xy=(2/3, 0.005), xytext=(0.55, 0.003), arrowprops=dict(arrowstyle='->'))
ax.annotate(f"Posterior max at {ps[max_posterior_index]:.2f}", xytext=(0.2, 0.03), xy=(ps[max_posterior_index], max_posterior), arrowprops=dict(arrowstyle="->"))
fig.legend()
fig.suptitle("Prior and Posterior Distributions of $p$ (MCMC)")
fig.savefig("mcmc.png", dpi=400)Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
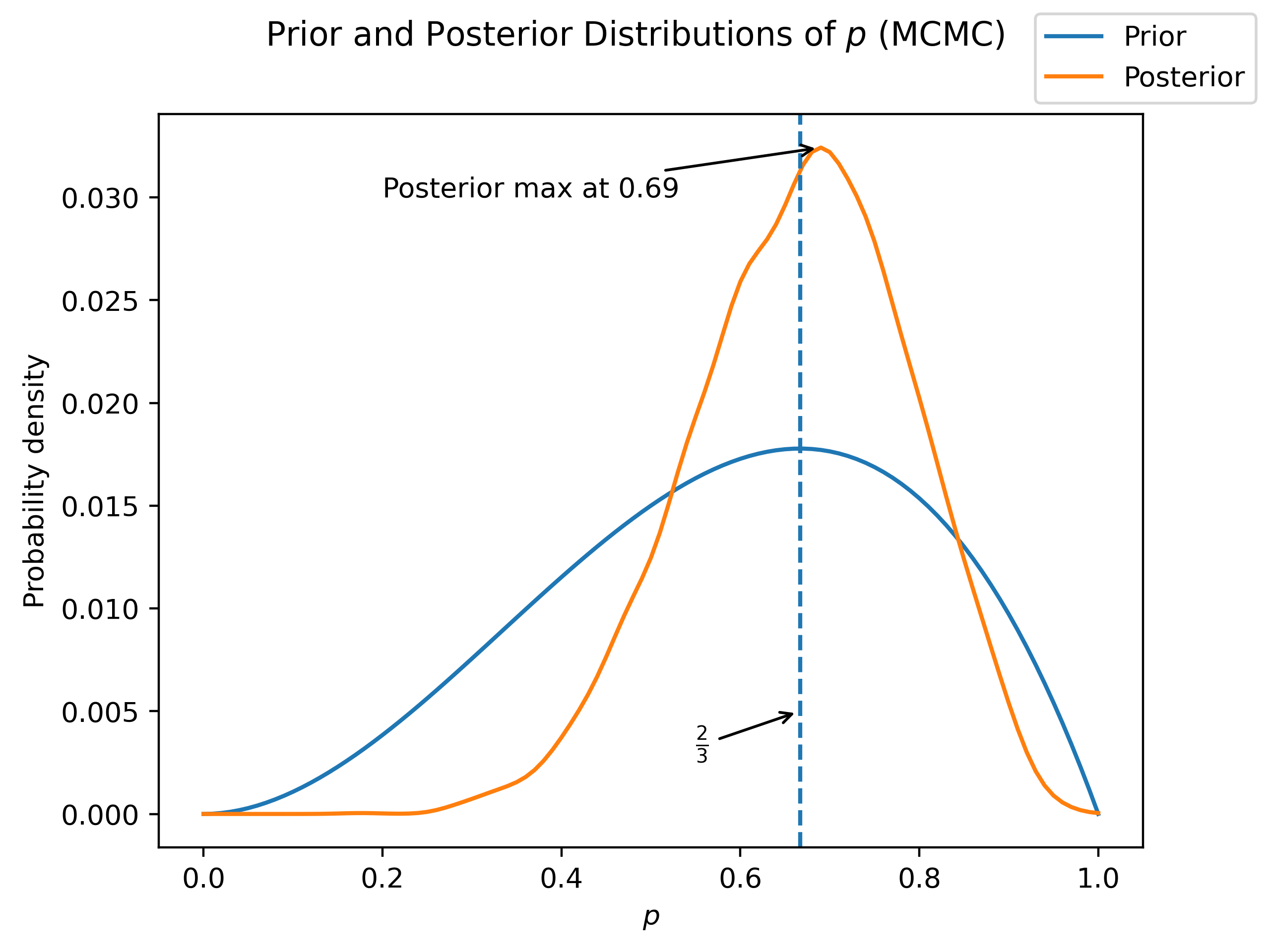
NUTS: [p]Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 2 seconds.Note that what we get from this process is not a distribution, but instead a set of samples. In oder to approximate the distribution, we can use a Gaussian Kernel Density Estimation (KDE).
We can access the sampled values of the variable we are interested in, , through the samples.posterior attribute. This attribute behaves like a dictionary where the keys are the names of the variables in the model. The actual samples are represented as an array of arrays, one for each of the chains used in the MCMC sampler. In order to get our combined sample, we simply combine the samples for each chain.
Unsuprisingly, we see very much the same results as with the grid approximation method. The main difference is that the posterior is now “bumpier”, as a result of the discrete sampling. If we needed to, we could decrease this by increasing the number of samples. However, for now this is good enough.
Conjugate Distributions
Our last method relies on the fact that we have a beta prior and a binomial likelihood, and that the beta is the conjugate prior for the binomial. What does this mean? Simply that there is a closed-form solution for the posterior - no sampling or approximations required! in order to see why, let’s say that we start with a prior which is and a likelihood which is . Then we have that the posterior is proportional to their product. The following is a (not at all rigorous) sketch of what the proof might look like:
Which is proportional to . Here we’re being very loose about the fact that everything is proportional, since at the end of the day we want a probability distribution, and so we’ll just divide out by whatever we need to in order to have the sum of probabilities be 1.
From this result, we should be able to get the prior analytically:
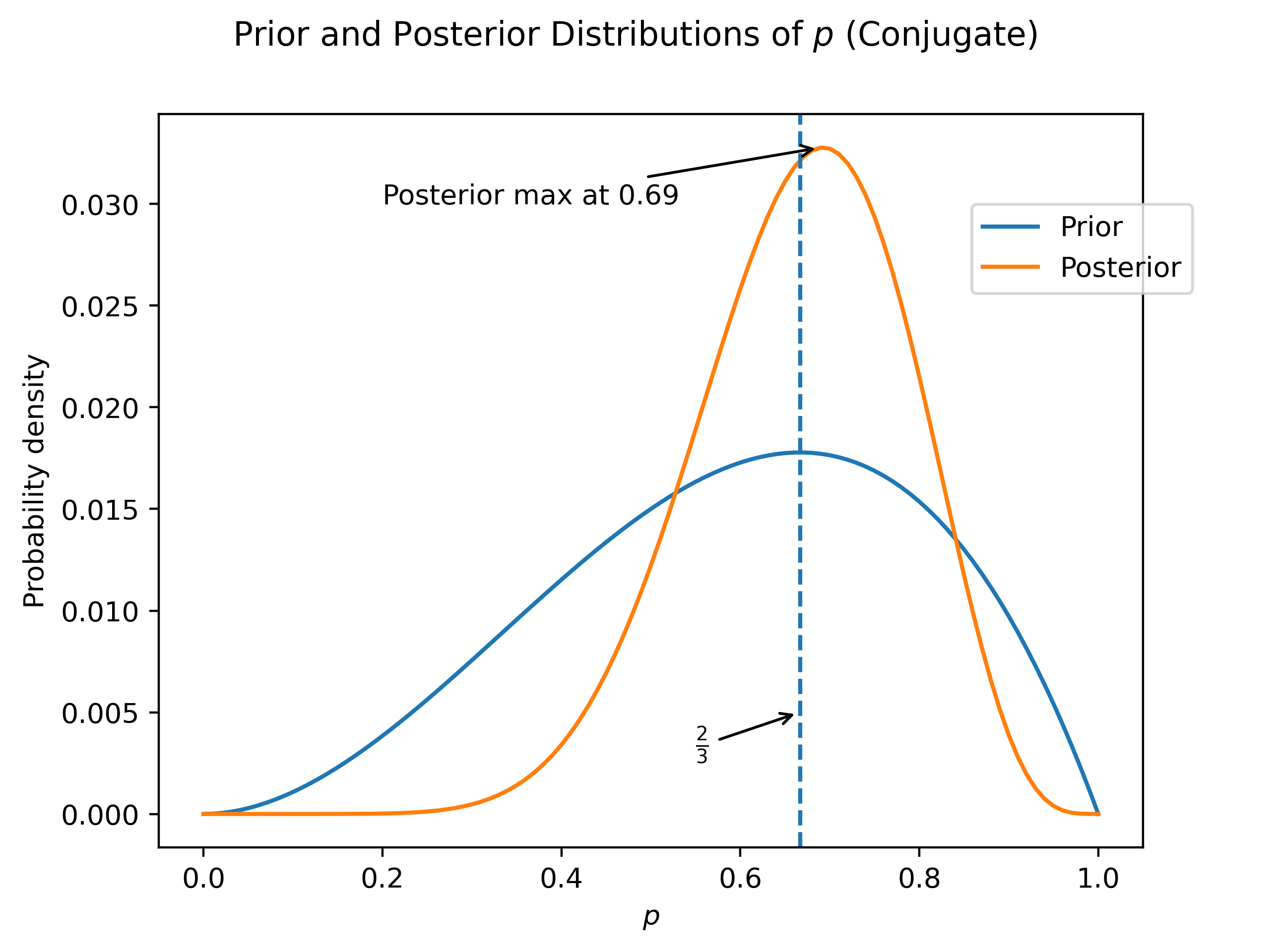
So the posterior should be .
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import beta
ps = np.linspace(0, 1, 101)
prior = beta(3, 2).pdf(ps)
posterior = beta(10, 5).pdf(ps) # unnormalized
posterior = posterior / np.sum(posterior) # normalized
max_posterior_index = np.argmax(posterior)
max_posterior = np.max(posterior)
fig, ax = plt.subplots()
ax.set_xlabel("$p$")
ax.set_ylabel("Probability density")
ax.plot(ps, prior / np.sum(prior), label="Prior")
ax.plot(ps, posterior, label="Posterior")
ax.axvline(x=2/3, linestyle="--")
ax.annotate(r"$\frac{2}{3}$", xy=(2/3, 0.005), xytext=(0.55, 0.003), arrowprops=dict(arrowstyle='->'))
ax.annotate(f"Posterior max at {ps[max_posterior_index]:.2f}", xytext=(0.2, 0.03), xy=(ps[max_posterior_index], max_posterior), arrowprops=dict(arrowstyle="->"))
fig.legend(bbox_to_anchor=(0.95, 0.8))
fig.suptitle("Prior and Posterior Distributions of $p$ (Conjugate)")
fig.savefig("conjugatePrior.png", dpi=400)Again, the results are similar. However, the process was certainly much easier!
So… Which One is Best?
The fact that we’ve gone and solved the same problem multiple times leads to the obvious question: which method is the best? As always, the answer is a disappointing “it depends”. For a very simple problem like this, using a conjugate prior is both quick and easy. However, the number of times where your problem will be solved by a conjugate prior is vanishingly small. There just aren’t that many distributions which are conjugate to each other. The grid method can be a good choice for problems which are similar to this one in that there aren’t too many dimensions / variables. However, as the number of variables increases the computational complexity will rise as roughly , which is obviously problematic. Using MCMC is a good choice for problems where the number of variables is large, at least in comparison to the other kinds.
And of course, there is at least one other common method which I did not cover - a quadratic (or Laplace) approximation, where we assume that the posterior is approximately normal. The reason for its exclusion is simply that I don’t use it very often, and so am not terribly familiar with it. However, it also has its strengths, particularly for quick solutions to low-dimensional problems.
Conclusion
We solved a simple problem in Bayesian statistic using three different methods: a grid approximation, Markov Chain Monte Carlo, and using a conjugate prior. For this simple problem the conjugate prior was the preferred method, but the different approximation methods have their own strengths in solving more complex problems.
Bibliography / Sources
- Analytics Vidhya - Introduction to Bayesian Statistics: Part 2: How Quadratic Approximation Works
- Machine Learning Mastery - Markov Chain Monte Carlo
- Matthew Conlen - Kernel Density Estimation
- McElreath, R. (2020). Statistical rethinking: A Bayesian course with examples in R and Stan (Second edition). Boca Raton London New York. CRC Press, Taylor & Francis Group.
- Wikipedia - Beta Distribution
- Wikipedia - Binomial Distribution
- Wikipedia - Conjugate Prior